---
title: "cliche - Python CLIs for humans and LLMs"
subtitle: "annotate a function, install it, run it"
date: 2026-04-30
---
Over the last 10 years I've created quite some tools in open-source (yagmail, textsearch, contractions, shrynk, and others), but in the AI era this has become more interesting than ever. With LLMs, the pesky and time-consuming tasks that used to sit on the bottom of my TODO list are suddenly achievable without getting tired - the kind of work where the design is clear but the typing is just a chore.
This post is about a small library that's been on that list for a long time, and which I am finally happy enough with to share publicly.
### A bit of history
I created the `cliche` package a few years ago and it had been used at the companies I worked at before. I never made the push to publicly announce it since it had a lot of rough edges - things that I knew about, that I knew how to fix, but that would each take a Saturday to actually do. So it sat there on PyPI, used by a small group of people who knew about it, and not really documented for anyone else.
Over the last few weeks (which is honestly very long when using a lot of LLMs) I have built upon the package, polished the rough edges, and added a bunch of new things on top of it. I hope it will be useful to the Python ecosystem.
While the code was largely generated by an LLM, I've written this post myself to ensure it remains personal and avoids the 'AI slop' label - please give it an honest chance :)
So without further ado, I am pretty excited to announce the (mostly finished) preview of cliche:
- [https://github.com/kootenpv/cliche](https://github.com/kootenpv/cliche)
- [https://pypi.org/project/cliche](https://pypi.org/project/cliche)
A v1 release is slated for June 2026 - the current work is the runway to that, and the public surface should stay stable through the cut.
### The core idea
The argument I want to make is that turning a Python function into a CLI should not require you to learn a CLI framework. You already wrote the function. You already wrote the type annotations. The CLI should just fall out of that.
In `cliche`, all you'd need to do to make a CLI from python code is to annotate a function:
```python
# calc.py
from cliche import cli
@cli
def add(a: int, b: int):
print(a + b)
```
Then run `cliche install calc` and you can call it from your shell:
```
calc add 2 3 # → 5
```
That's the whole *surface* of the library. No subparsers, no `add_argument` calls, no manual help strings. Type annotations become argparse types, defaults become flags, docstrings become `--help` text. No re-declaration.
Existing libraries each take a different stance on this: `click` and `typer` ask you to restructure code around decorators and argument definitions. `argparse` works but is verbose. `fire` is fast but guesses too much. `cliche` takes a different route: **your function signature is your CLI**.
There's not much more you need to know about the library to be able to use it. You can just bolt it onto your existing functions and it should generally work. It supports `pydantic`, `protobuf`, and `enum` out of the box, plus `Path`, `date`, `datetime`, `list`/`tuple`/`set`/`frozenset`, `dict[str, int]`-style flags, and `async def` - which together cover the cases I tend to run into when making internal tools.
### Fast on purpose
One thing I cared about a lot is startup time. CLIs that take half a second to print `--help` are an everyday papercut, especially when you've wired them into shell prompts, tight loops, or test harnesses.
cliche stays under 50 ms even in large packages because of two design choices:
- **AST-only scanning.** `@cli` is detected from source text, not by importing your code. So if your package has 100 files with heavy top-level imports, scanning them does not execute any of those imports. Only the module containing the invoked command is imported, lazily.
- **Per-file mtime caching.** Parsed signatures live in `~/.cache/cliche/`. Editing a file, adding a function, renaming one - the next invocation re-parses only what changed, and big changes fan out across CPUs.
A nice side-effect: `@cli` is a runtime no-op. You can unit-test your decorated functions as plain Python - no framework mocks, no fake argparse, nothing to stub.
Although it currently also does the help messages and wrong format parsing using C, which can be like a 20-50x speedup from using Python, to under 10ms.
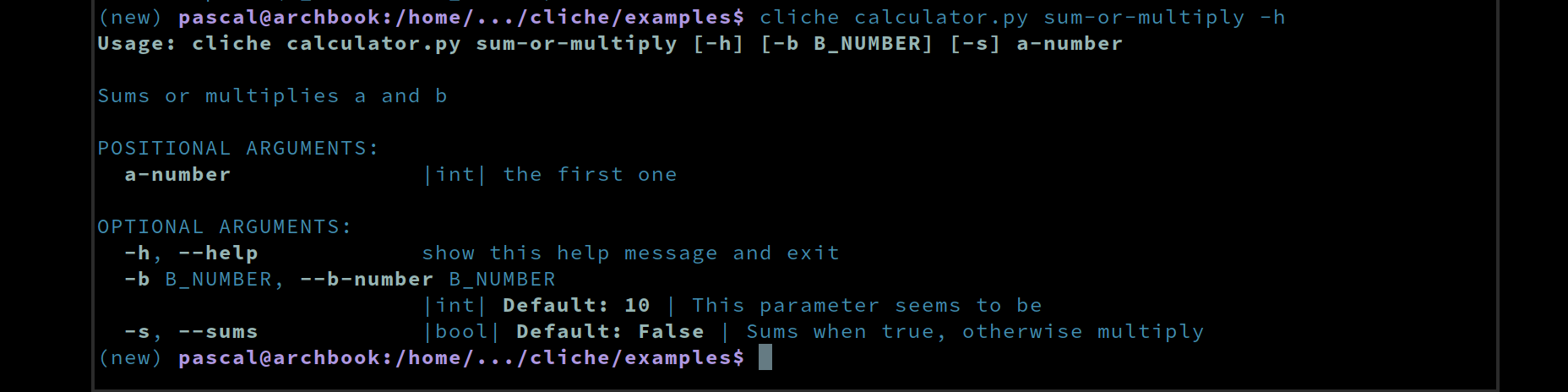
### Help that renders well
Docstrings *are* the help text. The first line becomes the command summary, each `:param name:` line becomes per-arg help, and `--help` renders with color, short-flag hints, type markers, and defaults so users can scan it fast:
Nothing to keep in sync: update the docstring, `--help` updates on next run.
It supports the 3 main flavors of param styling: sphinx, google and numpy style.
### Optimized for humans *and* LLMs
I added a lot of functionality to try to make it very nice and usable for humans (good help output, sensible defaults, decent error messages), while at the same time optimizing it like crazy for AI as well. The latter is something I haven't seen many libraries focus on yet, and I think it's where things are going.
For this, I added `--llm-help` to both cliche itself as well as the tool that you create. Where `--help` is laid out for humans skimming a terminal, `--llm-help` is dense, structured, and tailored for an LLM context window: every command, every signature, every enum, every default in a compact spec.
Any tool you create will inherit this out of the box:
```bash
mytool --llm-help
```
I built two benchmarks in the repo (`scripts/bench_llm_parsing.py` and `scripts/bench_llm_library_gen.py`) that measure round-trip quality across Claude, Gemini, Codex, and a local Qwen model. The first asks: do models correctly consume `--llm-help` and emit valid argv for the described CLI? The second asks: given the `cliche --llm-help` guide, can models generate *working* library source that installs and runs? Both have been useful for tightening the spec until current frontier models hit 100% on the parsing benchmark.
The bigger goal here is that I would really hope to get this to be used (or at least understood by default) by LLMs such that you can say "make a python CLI tool" without having to refer to the help at all. The library is small enough and the surface is opinionated enough that I think this is achievable.
For example, try these LLM prompts:
- `generate python cli using cliche for the functions ..., ...`
- `convert this app into a python cli using cliche`
- `replace argparse with python cliche`
In my own usage, the third one in particular has been a nice unlock - I have a handful of older internal scripts where the argparse boilerplate is longer than the actual logic, and converting them is now a one-prompt operation.
### Feedback wanted
It's currently not in a form where I can promise no breaking changes. I hope that people can find the blindspots so that I can make everything resilient and it'll be more battle-tested. The usage of cliche should not really change at this point, but I suspect some work is needed to avoid all possible bugs you might encounter, especially around weirder type annotations or edge-case argument combinations.
I really hope to get a lot of (constructive) positive (or negative) feedback. Obviously, while I put a lot of effort in, it can easily have huge blindspots, so I hope you give it a try and report back.
Thanks for your time!
---
This post is also crossposted on [dev.to](https://dev.to/kootenpv/announcing-cliche-ebm) if that's where you'd rather discuss it.